Au cours de la dernière décennie, les développements de l'apprentissage automatique ont considérablement modifié les pratiques professionnelles. De nombreuses décisions sont désormais prises à partir de résultats d’algorithmes intelligents, dans des domaines allant du traitement automatique des langues, à la détection de fraudes ou encore aux diagnostics médicaux. Le secteur financier n’a pas échappé à ces développements et a déjà intégré certains de ces algorithmes au sein de ses activités, tels que par exemple les agents conversationnels pour la relation client.
Une activité financière particulièrement impactée par les développements récents de l’apprentissage automatique est celle de la notation de crédit. Depuis de très nombreuses années, les établissements de crédit s’appuient sur des approches économétriques pour filtrer au mieux les emprunteurs potentiels, en fonction de leur solvabilité estimée. Or, les algorithmes d’apprentissage automatique ont une supériorité démontrée dans leur capacité prédictive du défaut probable des emprunteurs, par rapport aux modèles économétriques traditionnels de notation de crédit. Ils souffrent cependant d’un défaut majeur pour l’industrie de la notation de crédit et pour les régulateurs bancaires, à savoir leur manque d’interprétabilité. L’objet de notre recherche est de proposer un modèle original de notation de crédit combinant les avantages prédictifs des algorithmes d’apprentissage automatique à l’interprétabilité des méthodes économétriques traditionnellement utilisées dans ce domaine.
L’apprentissage automatique pour la notation de crédit : entre avantage prédictif et manque d’interprétabilité
Historiquement, la notation de crédit s’appuie sur des approches économétriques telles que l’analyse discriminante ou les modèles de survie. Parmi ces approches, la méthode de référence incontestée est le modèle de régression logistique. En effet, outre ses performances prédictives relativement bonnes, la popularité de cette approche provient de sa simplicité et de sa flexibilité permettant d’obtenir des résultats facilement interprétables. Plus précisément, ce modèle estime la probabilité de défaut de crédit d’un emprunteur à partir de certaines de ses caractéristiques individuelles, telles que le niveau de revenu, l’âge ou le type d’emploi. Cette probabilité est ensuite comparée à un seuil de risque limite déterminé au préalable par l’institution de crédit : si elle est supérieure à ce seuil alors l’octroi du crédit est refusé, la demande de prêt étant estimée trop risquée. Enfin, grâce à l’analyse des coefficients de la régression et des effets marginaux, les praticiens sont capables de quantifier l’importance et l’effet de chaque caractéristique individuelle sur la probabilité de défaut, et ainsi d’expliquer aux emprunteurs potentiels la raison de l’acceptation ou du refus de leur demande de crédit. Par exemple, si le coefficient associé au niveau de revenu des emprunteurs est estimé négatif, cela signifie que la probabilité de défaut diminue à mesure que le revenu augmente, et donc qu’un emprunteur ayant un niveau de revenu important a plus de chance de voir sa demande de prêt acceptée, toutes choses égales par ailleurs.
L’hégémonie de cette approche est aujourd’hui remise en cause par les algorithmes d’apprentissage automatique. En effet, des études récentes ont montré que les performances prédictives de certains algorithmes d’apprentissage automatiques sophistiqués, tels que la forêt aléatoire ou les approches de boosting, surpassent considérablement celles du modèle de régression logistique (Paleologo et al., 2010 ; Lessmann et al., 2015). Ce gain en termes de performance prédictive provient du fait que ces algorithmes sont capables de capturer automatiquement n’importe quel type de relation, notamment des relations non linéaires complexes leur permettant d’atteindre des performances prédictives bien meilleures que celle de la régression logistique.
Malgré cet avantage en termes de performance prédictive, les algorithmes d’apprentissage automatique ont certaines limites pour la notation de crédit, dont leur manque d'explicabilité et d’interprétabilité. Contrairement au modèle de régression logistique, la relation étudiée par ces algorithmes est inconnue a priori par l’utilisateur et aucun coefficient n’est obtenu à l’issue de leur utilisation : seule la probabilité de défaut estimé est connue in fine. L’effet des caractéristiques individuelles sur la probabilité de défaut est ainsi inconnu des praticiens, et c’est la raison pour laquelle ces algorithmes sont souvent considérés comme des « boîtes noires ». Dans ce contexte, il est très difficile, voire impossible, pour les praticiens d’expliquer les raisons d’un refus ou d’une acceptation de crédit aux emprunteurs potentiels. C'est aujourd’hui la principale faiblesse des algorithmes d’apprentissage automatique pour la notation de crédit, qui limite leur utilisation par les établissements de crédit, malgré leurs avantages prédictifs, puisque les praticiens doivent être capables d’expliquer aux régulateurs mais également aux emprunteurs potentiels le processus d’approbation de crédit. Cette limite a été récemment soulignée par les régulateurs financiers vis-à-vis de la gouvernance de l’intelligence artificielle et de son utilisation dans les processus métiers (ACPR, 2020 ; EBA, 2020).
Un modèle de notation de crédit hybride (Penalised Logistic Tree Regression) alliant performance prédictive et interprétabilité
Pour pallier les limites de la régression logistique et des algorithmes d’apprentissage automatique, nous proposons une approche hybride de notation de crédit intitulée « Penalised Logistic Tree Regression » (PLTR), dont l'objectif principal est de trouver le meilleur compromis entre performance prédictive et interprétabilité.
D’une part, ce modèle permet d’améliorer la capacité prédictive du modèle de régression logistique, par le prétraitement des données et l’ingénierie des fonctionnalités, et plus précisément par l’extraction de relations non linéaires des caractéristiques individuelles, à partir de techniques issues de l’apprentissage automatique. Pour ce faire, notre approche procède en deux étapes. L'objectif de la première étape est de construire de nouveaux prédicteurs à partir des variables explicatives originales. Formellement, des arbres de décision à une et deux divisions sont construits pour chaque variable et couple de variables originales afin de capturer des effets de seuil endogènes univariés et bivariés. La Figure 1 illustre cette première étape à partir d’un exemple hypothétique reposant sur le revenu et l’âge des emprunteurs.
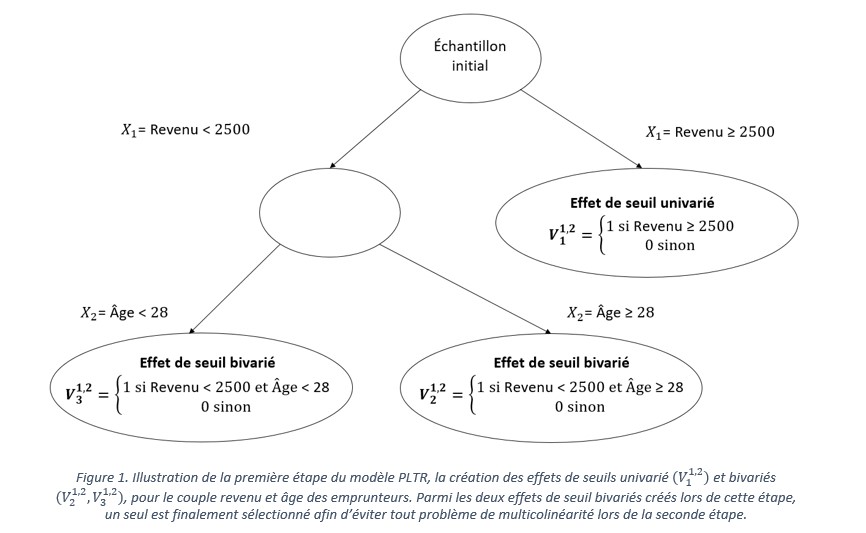
Dans une seconde étape, ces effets de seuil endogènes sont introduits dans une régression logistique afin de permettre au modèle de capturer de potentielles relations non linéaires, contrairement au modèle de régression logistique standard. Nous montrons par des simulations de Monte-Carlo et plusieurs applications empiriques que le modèle PLTR permet d’obtenir des prédictions plus précises que celles du modèle de référence de l’industrie. Dans notre application principale, nous améliorons la prédiction du risque de défaut de l’ordre de 23 %, et cette amélioration est confirmée par des exercices de robustesse effectués à l’aide de plusieurs bases de données, indicateurs de performances et tests de diagnostics. Dès lors, cette approche permet d’atteindre des niveaux de performances prédictives similaires à ceux des algorithmes d’apprentissage automatique.
D’autre part, notre modèle répond au manque d'interprétabilité des méthodes d'apprentissage automatique. S’appuyant sur le modèle de régression logistique, notre approche en conserve l’interprétabilité grâce à l’interprétation des coefficients estimés et des effets marginaux. De plus, les effets non-linéaires introduits dans le modèle de régression logistique lors de la seconde étape s’interprètent facilement : ces effets de seuils prennent la forme de simples variables binaires, dont les règles de décisions sont parcimonieuses et construites uniquement à partir d’une ou deux variables originales. Ainsi, l’interprétation des coefficients associés à ces effets de seuil est identique à celles des variables binaires traditionnellement introduites dans un modèle de régression logistique, et permet donc à notre approche de conserver sa transparence.
Notre modèle permet également de s’affranchir de prétraitements ad hoc ou heuristiques sur lesquels reposent les régressions logistiques, puisque nous utilisons une approche automatique, sans a priori sur l’existence, le sens ni l’ampleur des relations entre les variables d’intérêt pour la décision d’octroi de crédit.
Enfin, nous montrons que le modèle PLTR est intéressant d'un point de vue économique : dans notre application principale, il permet de réduire les coûts d’erreur de classification de 18 % par rapport à ceux du modèle de régression logistique de référence.
Références
ACPR (2020). Governance of artificial intelligence in finance. Autorité de Contrôle Prudentiel et de Résoluton.Discussion papers publication, November, 2020.
EBA (2020). Report on big data and advanced analytics. European Banking Authority, January, 2020.
Lessmann, S., Baesens, B., Seow, H.-V. , & Thomas, L. C. (2015). Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research. European Journal of Operational Research, 247, 124–136.
Paleologo, G., Elisseeff, A., & Antonini, G. (2010). Subagging for credit scoring models. European Journal of Operational Research, 201 (2), 490–499.